【Datawhale AI 夏令营】Task3-模型微调
一、微调
1.1 什么是微调
在预训练模型的基础上,针对特定任务或数据集进行进一步的训练,以适应更具体的应用场景。
1.2 微调的意义
- 上下文理解提升:使用的特定数据集可以帮助模型更好地理解特定任务的上下文,从而在推理时能够考虑到更多的相关信息和细节。
- 性能优化:使其在处理该任务时达到更高的准确率和更低的错误率。这对于需要高可靠性和准确性的推理任务尤为重要。
- 减少数据需求:对于一些数据稀缺的领域或任务,微调可以在相对较少的数据量下实现较好的性能提升,因为模型已经具备了大量的通用语言知识。
- 适应性增强:微调使模型能够更好地适应特定用户或场景的需求,提供更加个性化和定制化的推理服务。
二、LoRa
2.1 什么是LoRa
LoRA(Low-Rank Adaptation)微调是一种高效的模型微调技术,特别适用于大型预训练语言模型的适应性调整。LoRA的核心思想是通过引入低秩矩阵来调整模型的权重,从而在不显著增加模型参数数量的情况下,实现对模型的微调。
通俗点说就是,在原有的权重矩阵之外,增加一组更小的矩阵,这些矩阵可以视为对原有权重的小幅调整。这些调整矩阵(低秩矩阵)可以以较小的成本学习到新任务的特定模式,而无需改变预训练模型的大部分权重。
2.2 LoRa的优势
可以针对不同的下游任务构建小型 LoRA 模块,从而在共享预训练模型参数基础上有效地切换下游任务。
LoRA 使用自适应优化器(Adaptive Optimizer),不需要计算梯度或维护大多数参数的优化器状态,训练更有效、硬件门槛更低。
LoRA 使用简单的线性设计,在部署时将可训练矩阵与冻结权重合并,不存在推理延迟。
LoRA 与其他方法正交,可以组合。
2.3 LoRa原理
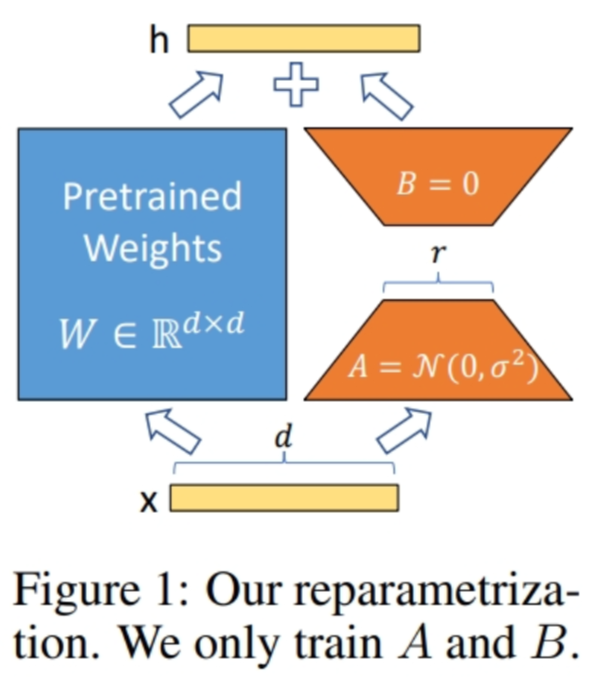
2.4 通俗易懂
想象一下,有一个非常复杂的拼图,拼图代表了一个预训练好的大型语言模型。拼图已经完成,而且做得非常好,它能够识别和理解各种语言模式和语义。但是,当你需要这个拼图适应一个新的场景或任务时,比如说要它理解一种特殊的行业术语或者特定的文化背景,你不想打乱整个拼图,因为那会破坏它原有的功能和性能。
LoRA就像是为这个拼图添加了几块额外的、可移动的小拼图。这些小拼图被设计成可以插在原拼图的某些部分上,改变那些部分的功能,但不会影响整个拼图的完整性和稳定性。这些小拼图是专门定制的,它们只需要学习如何适应新任务,而不是整个模型的所有部分。
2.5 后话
跟着相关的参考资料,目前我个人的理解是LoRa就是使用模型和部分数据,来生成一个小模型,然后将小模型整合进大模型中。使大模型对特定数据的更好的理解和处理。
感觉通过LoRa进行微调,是可以满足开源模型服务实际业务需求的。所以后面打算继续学习一下LoRa的使用,也会将相关的学习记录在本博客下。
三、vllm加速
3.1 vllm
[vLLM(Virtual Large Language Model)是一个由伯克利大学LMSYS组织开源的大规模语言模型高速推理框架。它的设计目标是在实时应用场景中大幅提升语言模型服务的吞吐量和内存使用效率。vLLM的特点包括易于使用、与Hugging Face等流行工具无缝集成以及高效的性能。
3.2 vllm的用途
主要用来加速大模型的文本生成过程。当涉及到长文本生成或需要处理大量输入时,大模型的计算成本较高(好像主要是电费,跟挖矿的了)。
vllm通过优化模型的推理流程,来解决大模型的实时部署和高性能生成。
3.3 vllm使用步骤
- 安装vllm库。
- 加载预训练的模型和配置。
- 配置vllm参数,如批量大小、最大序列长度等。
- 调用vllm的API进行文本生成。
3.4 通俗易懂
想象一下,你正在玩一个数独,比较复杂,每次你填下一个数后,可能会影响后续所有可能的选择。如果你每次都要重新思考所有可能的后续选项,非常耗时。vllm就像一个聪明的游戏助手,它会记住你已经填过的数,并且只给你接下来合理的几个选项,这样你就不用考虑那些明显不合适的数,从而大大加快了游戏的速度。
vllm根据已经生成的文本动态调整生成的词汇范围,从而加速了文本生成的过程。
四、多路LLM投票
4.1 什么是多路LLM投票
即多模型融合或模型集成,是一种在多个大模型之间采用决策融合策略的方法,用于提高预测的准确性和稳定性。
这种方法在机器学习和深度学习领域中很常见,尤其在面对复杂或高风险的应用场景时,比如自动驾驶、医疗诊断或金融预测等。
4.2 Baseline中的实现
其实看到讲义中写的实现逻辑(通过三次结果推理,将选择答案最多的结果作为最终结果),我突然就想起了一个区块链的共识机制——拜占庭算法。与之类似,大概得意思就是,少数服从多数。
五、后续
到目前为止,感觉有开源模型及其开源生态的加持,大模型的开发和应用,对于一般企业来说不是什么太难的事,重点就是在微调和量化上。微调能解决模型服务于业务需求。而量化可以解决,在较低性能的机器上运行大模型。
个人感觉,大模型在AI领域近几年很流行,也比较趋于成熟化了。但是训练数据,运行环境要求还是不太完美。感觉后面肯定会有更好的解决方案,也会从大模型这一块衍生出更多新的AI技术。
本Task所需文件: